Almost every “AI-powered” data tool looks the same under the hood. A dashboard built for a human, with forms, wizards, a job list, a settings page, and a chat box wedged into one corner. You ask a question, the model writes some SQL or drafts a config, and hands it back to you to go click the buttons. The model is smart. The product is still something a person runs by hand.
That’s a copilot. Fine as far as it goes. But it didn’t remove the bottleneck, it just moved it onto the person still doing the clicking.
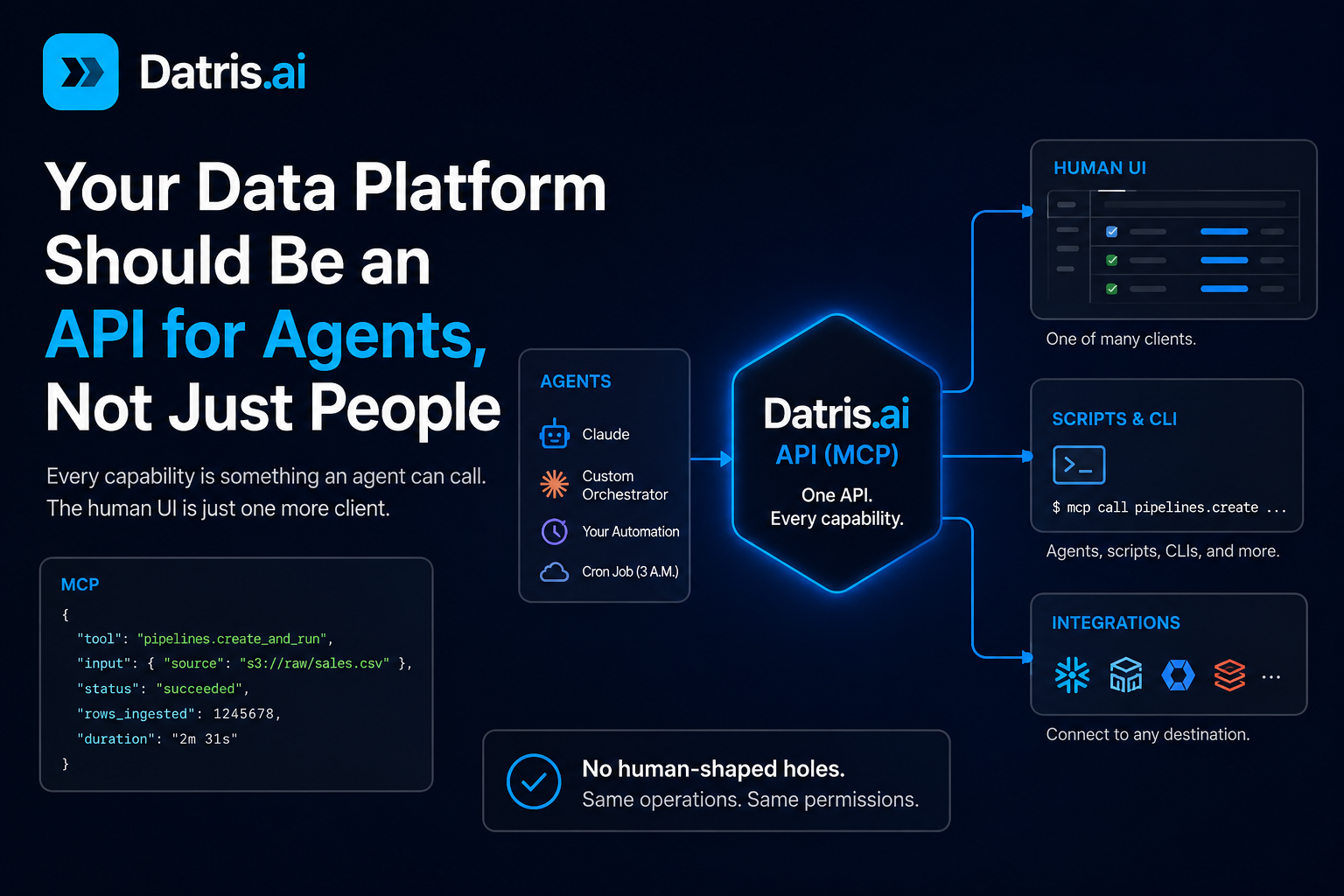
Agent-native flips that. You don’t add a model to a product built for people. You build every capability as something an agent can call, and the UI turns into one more client hitting the same surface. Anything a person does by clicking, an agent does by calling. Same operations, same permissions, no second-class path for the machine.
The tell: is there a human-only operation?
Pick any capability in the product. Create a pipeline. Kick off an ingest. Run a transform, search the output, rotate a credential. Now ask whether an agent can do it start to finish with nobody in the loop.
For a copilot the answer is usually no. It drafts the config; a person pastes it into a form and hits save. It writes the query; a person runs it. The agent talks, the human does the work. There’s a human-shaped hole in the middle of every workflow.
Agent-native means that hole isn’t there. The whole lifecycle (define, ingest, validate, transform, run, monitor, query, answer) reachable through one protocol. The UI is there for when a person wants to drive. It isn’t the only way in.
Why MCP is the right shape for this
Before MCP, “let an agent use our platform” meant a custom integration for every model and every orchestrator, and then maintaining all of them forever. What the platform could do and how you reached it were welded together.
MCP pulls them apart. You publish your tools once, what each one does, what it takes, what it returns, and any MCP client discovers them and calls them. Claude drives it. Your own orchestrator drives it. A cron job drives it at 3 a.m. while you sleep. Write the capability once and swap the drivers however you like.
That’s what turns “API for agents” from a tagline into something you can ship. The agent isn’t reverse-engineering a private endpoint. It reads a declared surface at runtime and operates it the way you’d operate a screen, minus the screen.
What this looks like when it’s real
Take the loop an analyst actually runs. A file shows up. Somebody works out its shape, writes rules to catch the bad rows, reshapes it to fit the destination, stands up a pipeline, runs it, waits for it to finish, then queries the result to answer whatever question kicked the whole thing off.
On an agent-native platform that entire loop is callable. The agent looks at the incoming data and proposes a structure. It generates the quality checks and the transform. It creates the pipeline in one atomic call instead of leaving a half-built thing parked in a form. It runs the job and polls it to the end, rather than calling submit and walking away like the work is done. Then it queries the output and answers the question, over the same surface, against whatever the destination happens to be.
Notice what’s missing: no “and then the user clicks.” The person sets the goal and judges the result. That’s the part of the loop where a human is actually worth having.
Parity is the part you have to defend
The trap is letting the agent surface fall behind the UI. A new capability ships in the dashboard and the tool to do the same thing lands “later.” I’ve watched teams do that three or four times and end up right back where they started: a human-only product with an agent stapled to the side, which is the exact thing they set out to avoid.
So the rule is parity. A capability isn’t done until it’s callable. The UI and the agent are two clients of one surface, and neither one gets a back door the other can’t reach. Hold that line and you keep a platform an agent can run, not just narrate.
That’s the bet. The main user of a data platform might not be a person anymore, and it should work just as well when it isn’t. A smarter chatbot in the corner won’t get you there. Building every capability so an agent can operate it will.
Todd Fearn is the founder and CEO of Datris, an open-source, agent-native data platform built on MCP. He’s spent 30+ years building production data infrastructure at places like Goldman Sachs, Bridgewater, Deutsche Bank, and Freddie Mac, and now runs the data-pipeline consultancy IData Corporation. He writes about agent infrastructure, data engineering, and the unglamorous parts of making both actually work.