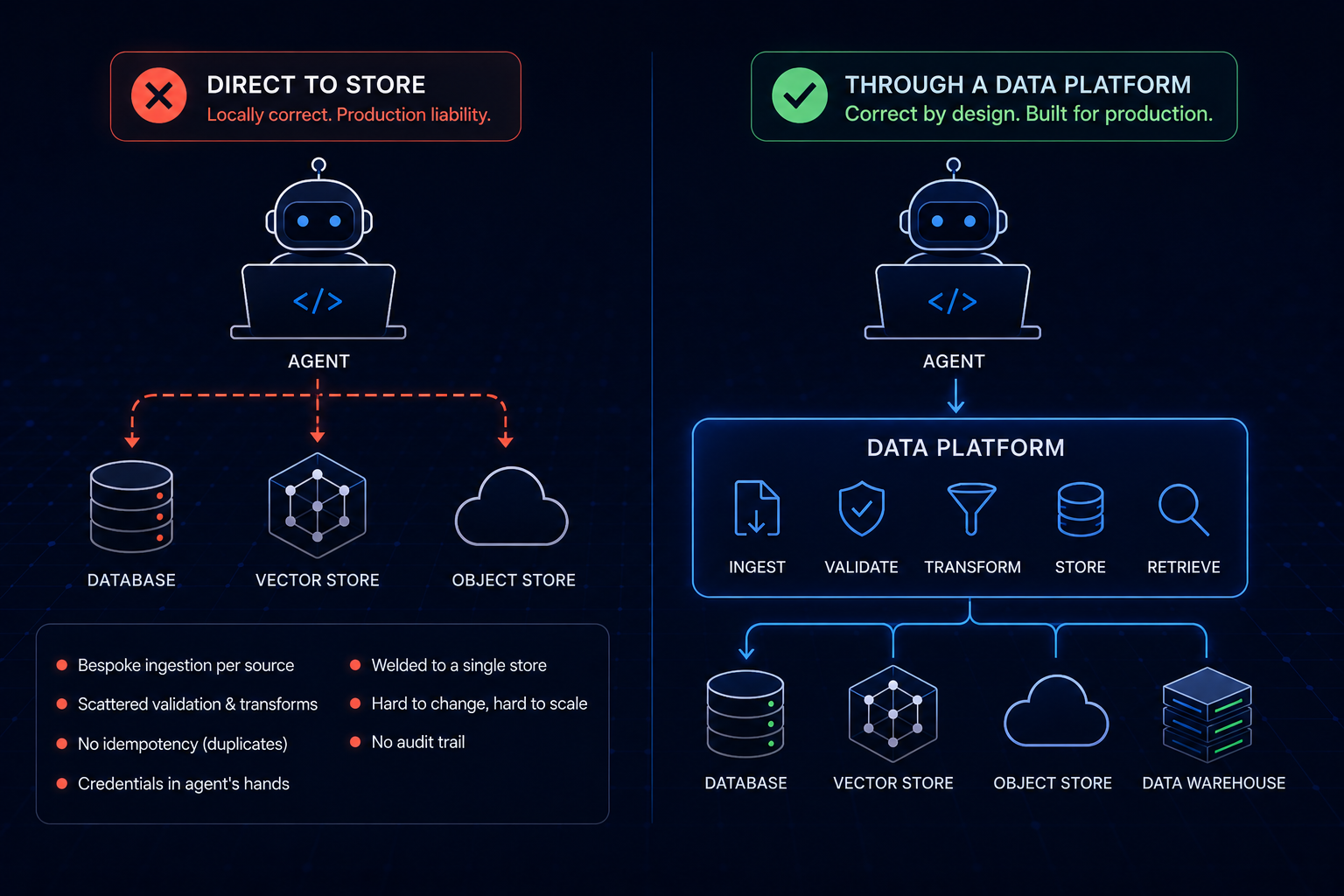
Open up Claude Code, or Cursor, or whatever coding agent you like, and tell it to build an agent that stores data. Watch the first move. It reaches for a database driver. It installs a client library, opens a connection, and starts issuing inserts and queries straight against your store. Ask it to do retrieval and it will pip install a vector store client and write embeddings directly into it.
This is the default. It is also, almost always, the wrong architecture for anything you intend to run in production.
I don’t blame the agent. Direct integration is the locally correct move. It’s what every tutorial shows and what most of the code on the internet does. It’s what gets a demo working in twenty minutes. The agent is optimizing for “make it run now,” and writing straight to the store is the shortest path to running. The problem is that the shortest path to a working demo and the right path to a production system are not the same road, and the agent has no reason to know the difference.
What direct integration costs you
Here is what you actually get when the agent talks straight to the store. Every source needs its own bespoke ingestion code. The validation, if there is any, lives scattered through application logic the agent wrote inline. The schema is whatever the agent inferred from the first few records, so the day the source changes shape, you find out in production. There is no idempotency, so a rerun double-writes. The store’s credentials end up in the agent’s hands or its environment. And when you decide to move from one vector database to another, or add a second destination, you are rewriting agent code, because the agent baked one store’s client and write semantics into the application.
What you end up with is an agent welded to a single store, with the hard parts of data handling reimplemented inline and reimplemented badly. Calling that “an agent that uses data” is generous.
What a platform changes
A data platform changes what the agent is responsible for. Instead of issuing raw writes, the agent works through one interface that already knows how to ingest, validate, transform, store, and retrieve. The agent says what it wants to happen. It doesn’t implement how. The plumbing that sits under all of that, the fiddly part, belongs to the platform now, not the agent.
Correctness comes first
The payoff starts with correctness, because that’s where direct integration hurts first. Validation and transformation become configuration you can read and change, and they run the same way every time, before anything reaches the store, so a bad file bounces at the door instead of poisoning the table. Writes get idempotent too. The platform keys the destination on a natural key, so the agent can rerun a job after a failure and overwrite cleanly, no doubled rows. It doesn’t have to reason about a partial write. It just reruns.
You stop being locked to one store
You also stop being married to one store. Write to Postgres today and add a vector store tomorrow, and the agent never changes, because it calls the same capability and the platform handles the routing. Swap to a different vector database next quarter and it still never changes. Your retrieval layer is no longer hostage to whatever client library the agent installed on day one. The credentials never touch the agent either. The connection secrets live in a vault, the platform uses them, and the agent operates the capability without ever holding the key. In a regulated shop that’s the only access model you can actually defend.
RAG and the audit trail
RAG is the same story. Extraction, chunking, embedding, and the write into the vector store are pipeline steps you configure once, not logic the agent reinvents inline and gets subtly wrong every time. And you get an audit trail close to free on top of it. Every job carries a status and a record, so when something breaks you ask the platform what ran, with which inputs, and what came back, rather than piecing together the agent’s improvisation from logs.
Where the agent’s intelligence should go
The real reason to do this is about where you want the agent’s intelligence to go. When the agent is busy managing connections and write semantics, that’s effort it isn’t spending on the task you actually hired it for. Push the data plumbing down into a platform and the agent gets smaller and far easier to reason about. It works on the problem. The platform makes sure the data is handled correctly.
The intervention is cheap
None of this happens on its own, because the agent will not choose it for you. You have to hand it the platform’s interface and tell it to use that. Point it at the tools and tell it to leave the connection string alone. Once you do, the agent is perfectly happy to operate at that level. It was only writing raw inserts because that was the closest thing to hand.
So the next time you watch a coding agent spin up an integration, notice what it grabbed first. If it grabbed a database driver, you’re looking at a prototype that will quietly become production unless someone steps in. The intervention is cheap. Hand the agent a platform to operate and take the plumbing off its plate. Then let it get back to the work that needed an agent in the first place.
Todd Fearn is the founder of Datris.ai and has spent about thirty years building data infrastructure for financial institutions. He writes about making AI agents useful in real production systems.