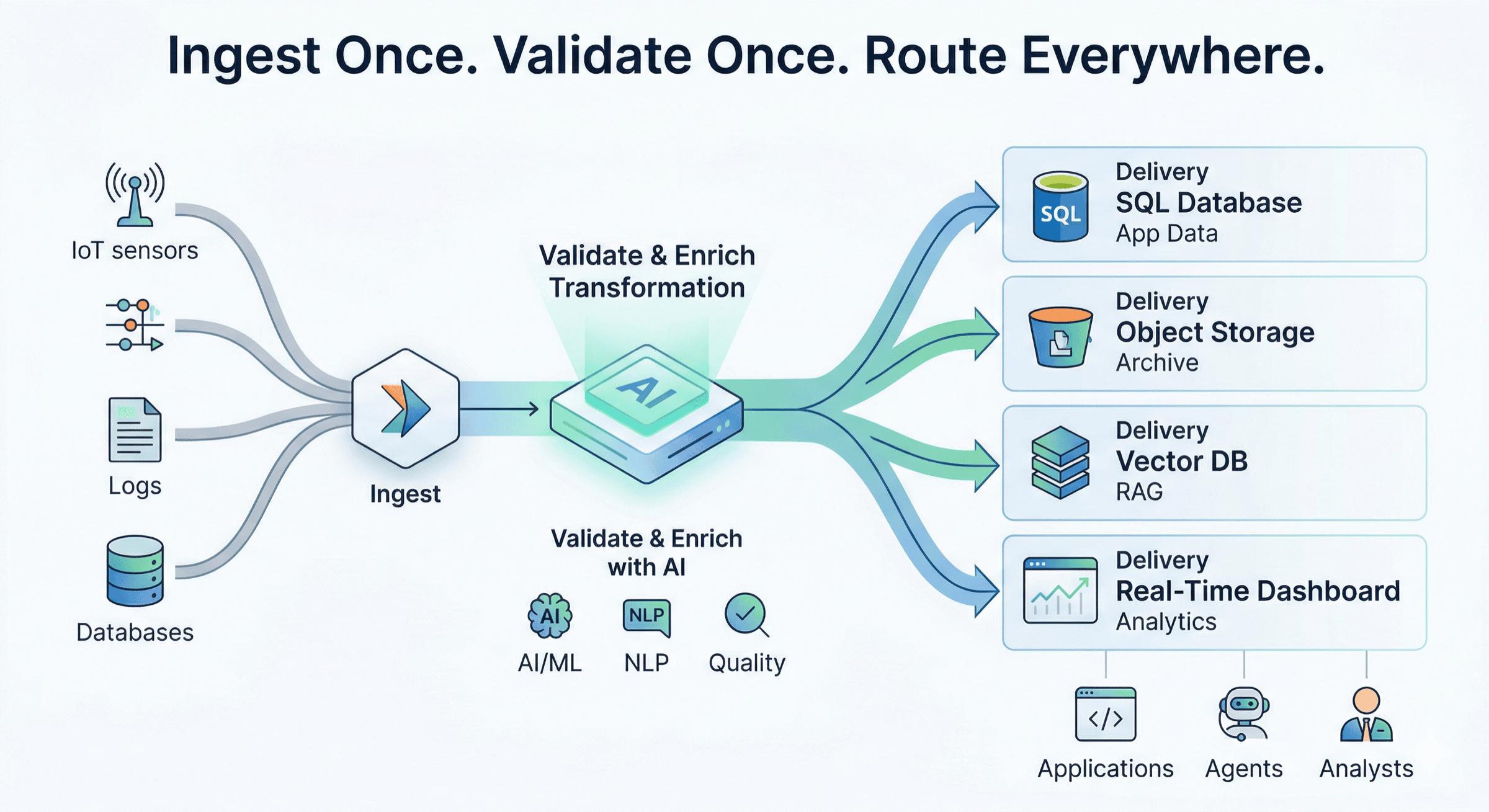
Most data pipelines were built around one assumption: move data from A to B.
That assumption is dead.
But it’s not just the destinations that changed. AI changed the entire pipeline.
Quality checks are no longer just schema validation and null checks — you write a rule in plain English and the platform validates with context. Transformations are no longer hand-coded scripts for every edge case — you describe what you want and the platform generates and executes the logic. The data engineer’s job shifts from writing plumbing to defining intent.
And when AI is enriching and classifying your data on the way through, the output isn’t just clean rows anymore. It’s ready for multiple consumers at once — applications, analytics systems, and autonomous agents — all with different requirements for how data should arrive.
Which brings us to the second thing that changed: destinations.
The same operational dataset now needs to land in multiple places simultaneously. One copy goes to Postgres for the application. Another hits object storage for retention. Another feeds a vector database for RAG. Another goes to search, a dashboard, a feature store, or a partner API.
This is the normal architecture now. Not the edge case.
Single-destination thinking breaks in the real world
Downstream consumers have different needs. That’s just reality.
A healthcare platform ingesting patient support transcripts needs to route to Postgres for case management, S3 for compliance retention, a vector database for semantic search, and MongoDB for flexible application access — all from the same data.
An e-commerce company taking product catalog updates needs to hit a transactional store for the storefront, Elasticsearch for search, a vector database for recommendations, and a warehouse for inventory analytics.
The old answer was to chain tools together. Load into one system, trigger a job, transform again, write somewhere else, then debug all of it when schemas drift or step three fails at 2am on a Tuesday.
That’s fragile. And most of the complexity is self-inflicted.
Ingest once. Validate once. Route everywhere.
What you actually want is simpler: define your schema, quality rules, and transformation once — then fan out to every destination that needs it.
Most platforms force you to do the opposite. You rebuild similar ingestion logic for each downstream system because the architecture assumes one output target per pipeline.
Datris takes a different approach. A single JSON config drives the entire pipeline — source, AI-powered quality rules, AI transformation, and all destinations. They all execute in parallel:
{
"name": "customer_interactions",
"source": {
"schemaProperties": {
"fields": [
{ "name": "customer_id", "type": "string" },
{ "name": "interaction_type", "type": "string" },
{ "name": "channel", "type": "string" },
{ "name": "message_body", "type": "string" },
{ "name": "sentiment_score", "type": "double" },
{ "name": "interaction_date", "type": "timestamp" }
]
},
"fileAttributes": {
"jsonAttributes": {
"everyRowContainsObject": false,
"encoding": "UTF-8"
}
}
},
"dataQuality": {
"aiRule": {
"instruction": "customer_id must be present and stable for the same user across records. sentiment_score must be between -1 and 1 when present. interaction_type must match the content and channel fields.",
"onFailureIsError": true
}
},
"transformation": {
"aiTransformation": {
"instruction": "Extract a short issue_summary from message_body. Normalize channel values to lowercase. Classify each interaction as billing, product, shipping, technical_support, or other and write it to a field called classification."
}
},
"destination": {
"schemaProperties": {
"dbName": "operations",
"fields": [
{ "name": "customer_id", "type": "string" },
{ "name": "interaction_type", "type": "string" },
{ "name": "channel", "type": "string" },
{ "name": "message_body", "type": "string" },
{ "name": "sentiment_score", "type": "double" },
{ "name": "interaction_date", "type": "timestamp" },
{ "name": "issue_summary", "type": "string" },
{ "name": "classification", "type": "string" }
]
},
"database": {
"dbName": "operations",
"schema": "public",
"table": "customer_interactions",
"usePostgres": true,
"useTransaction": true
},
"objectStore": {
"prefixKey": "customer-interactions/",
"fileFormat": "parquet",
"partitionBy": ["interaction_type"],
"writeMode": "append"
},
"pgvector": {
"tableName": "customer_interactions_rag",
"schemaName": "public",
"chunking": {
"strategy": "paragraph",
"chunkSize": 500,
"chunkOverlap": 50
},
"embeddingSecretName": "pgvector-embedding-secret",
"postgresSecretName": "pgvector-connection-secret"
},
"mongoDB": {
"dbName": "operations",
"table": "customer_interactions_docs",
"useMongoDB": true,
"keyFields": ["customer_id"]
}
}
}Notice what’s happening in that config. The aiRule isn’t a schema check — it’s a plain English description of what valid data looks like. The aiTransformation isn’t a script — it’s an instruction that generates and executes the logic, adding issue_summary and classification to every record. Then Postgres, object storage, pgvector, and MongoDB all written in parallel from that single enriched, validated dataset.
No four separate ingestion jobs. No duplicated quality logic. No schema drift between systems.
This matters more in the agent era
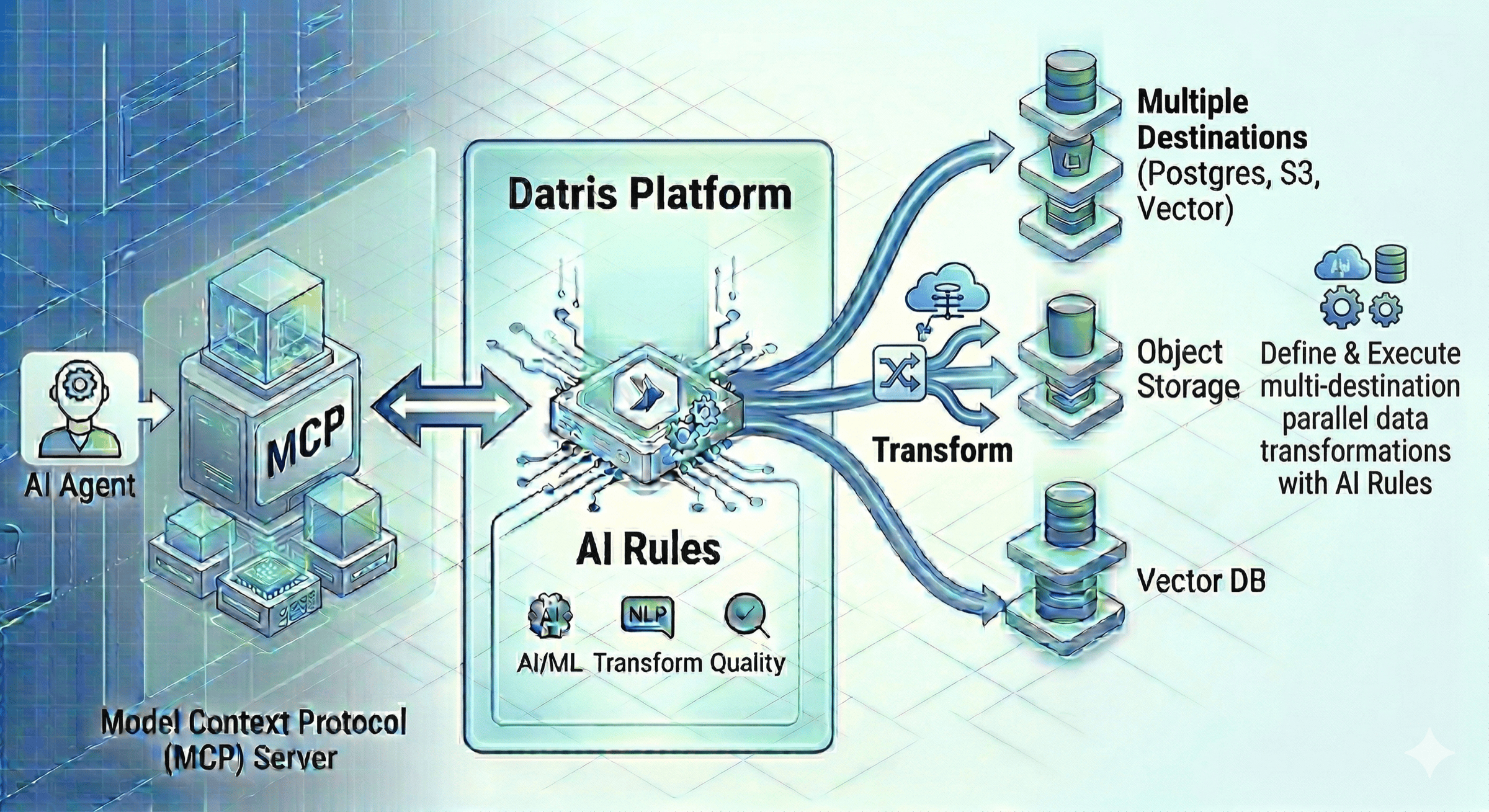
AI agents change the shape of the problem further.
An agent doesn’t want raw pipeline plumbing. It wants reliable access to the right form of data for the task.
An operations agent troubleshooting delayed shipments needs structured rows in Postgres for current status, historical payloads in object storage for audit, and semantically indexed delivery notes in a vector store for retrieval.
A healthcare support agent summarizing prior cases needs validated metadata in one system and embedded free text in another.
A field service agent diagnosing equipment failures needs operational event tables, unstructured maintenance logs, and AI-enriched summaries — all sourced from the same ingestion pipeline.
Multi-destination routing becomes strategic here. The pipeline stops being ETL. It becomes the control point where you decide how data is shaped, enriched, and delivered for applications, analytics, and agent workflows — in one pass.
The operational payoff
Less duplicated logic. Define schema handling, quality rules, and transformations once. Stop chasing mismatches across multiple jobs.
Better consistency. Your warehouse copy, app copy, and AI copy come from the same validated, enriched dataset — not three slightly different versions built by different teams.
Simpler failure handling. One place to inspect when something breaks. One set of logs. Datris explains failures in plain English, which beats handing someone a stack trace.
Faster iteration. When a new use case shows up, you add a destination — not redesign the whole pipeline.
That last one matters more than most teams realize. In most organizations, the hardest part of shipping an AI feature isn’t the model. It’s getting the right data, with the right quality checks, into the right system, without breaking what already works.
Config-driven is the right answer
When routing rules, quality rules, transformations, and destinations all live in config, teams can reason about the system clearly. Changes are reviewable. They’re versionable. Agents can interact with them safely.
That’s also why Datris exposes platform capabilities through MCP. Agents should be able to inspect pipelines, check quality results, run jobs, and help operators — without custom glue code for every integration.
The future data stack will be jointly operated by humans and agents. That only works if the platform is explicit, discoverable, and composable.
The shift that’s already happening
The market spent a decade optimizing how to move data into a warehouse.
The next phase is about preparing data for many consumers at once — applications, analytics, search, and autonomous agents. And doing it with AI doing the heavy lifting at every stage: validating with context, transforming with intent, routing with precision.
That requires a different mindset. Not single-destination. Not hand-coded transforms. Not brittle schema checks.
If you’re building modern data workflows — especially ones that need to support AI applications and agentic operations — the question worth asking is whether your platform can validate once, enrich once, and deliver everywhere.
If you want to see how we’re doing it: github.com/datris/datris-platform-oss and datris.ai.
Todd Fearn is the founder of Datris. He’s spent 30+ years building data infrastructure across financial services, including Goldman Sachs, Bridgewater Associates, Deutsche Bank, Freddie Mac, and others.