The demo always works. That’s not the problem.
The problem is what happens at 11:47 PM when the third API call in a six-step plan returns a 502, the agent has already committed two writes downstream, and nobody is awake to figure out which half of the world is now in a weird state.
I’ve spent thirty years building data infrastructure for places like Goldman, Bridgewater, and Deutsche Bank. The shapes of failure aren’t new. What’s new is that we’re letting language models drive the recovery, and most agent stacks I see still treat the first tool call as if it were the whole story.
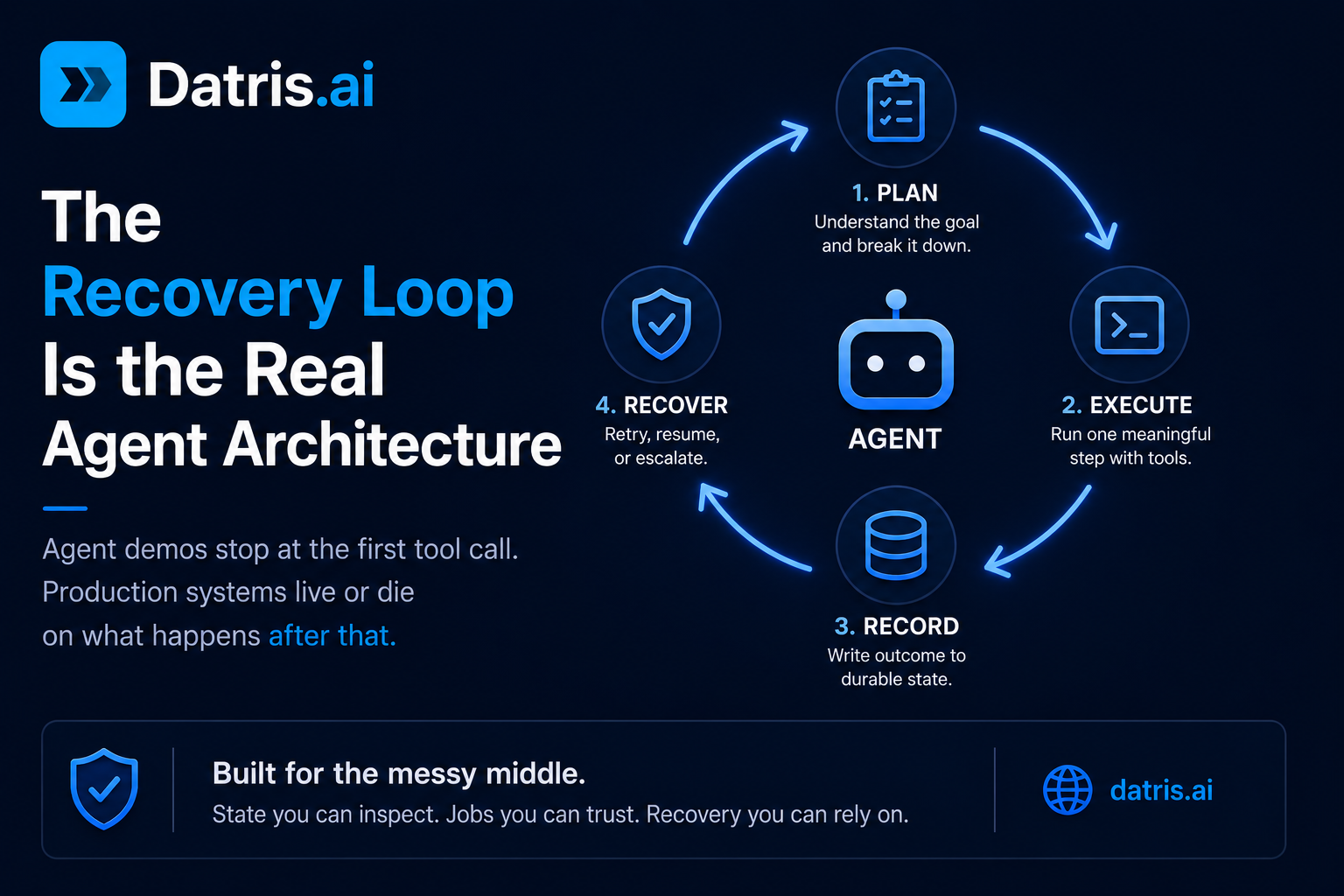
It isn’t. The first tool call is the easy part. The architecture lives or dies on what happens next.
First-pass success is a trap
There’s a clean linear story everyone tells about agents. User asks, model plans, tools run, result returns, applause. That story exists. It just isn’t the normal case once you connect anything to a live system.
Networks fail. Jobs run async. Rate limits kick in mid-batch. Permissions differ between environments. Data arrives late. A human edits the record while the agent is still reasoning about the old version of it.
If an agent summarizes a document twice, nobody cares. If it posts the same trade twice, books the same invoice twice, or re-runs an ingestion against the wrong destination, you have a real problem and probably a phone call.
So the design question isn’t “can my agent call tools.” It’s “what happens on step three when the world stops cooperating.”
Recovery needs state, not vibes
A lot of agent stacks still substitute log scraping and prompt-stuffing for actual state. The agent reads its own breadcrumbs and tries to infer what happened. That works until it doesn’t, and the failure mode is usually the agent confidently telling you a job finished while the job is still running, or has already failed quietly.
If you want real recovery, every meaningful operation needs a durable, structured record the agent can inspect without guessing — job ID, status, timestamps, error details, enough context to decide whether a retry is safe.
Here’s what that looks like for a Datris document tap — the actual response an agent gets from get_pipeline_status when it polls a multi-file run, where one file landed and another hit a downstream error (per-event audit trail elided for length):
{
"rollup": {
"allDone": true,
"status": "error",
"jobs": [
{
"pipelineToken": "f3a91e2c-7d04-4b6f-9c12-2a8e5d1c9b4a",
"pipeline": "sync_customer_orders",
"filename": "orders_north_2026-05-20.csv",
"status": "success",
"startedAt": "2026-05-20 23:47:02 UTC",
"lastEventAt": "2026-05-20 23:47:14 UTC",
"elapsed": "12.345 sec",
"lastError": null
},
{
"pipelineToken": "b9c4d1f8-3e21-4a87-b056-fa7c2e9d8b13",
"pipeline": "sync_customer_orders",
"filename": "orders_south_2026-05-20.csv",
"status": "error",
"startedAt": "2026-05-20 23:47:14 UTC",
"lastEventAt": "2026-05-20 23:47:18 UTC",
"elapsed": "4.123 sec",
"lastError": {
"processName": "upsert_destination",
"description": "502 from downstream API on confirmation"
}
}
]
},
"events": [/* per-event audit trail, elided */]
}Now the model isn’t hallucinating system truth. It’s reading it. The north file landed; the south file failed at the destination upsert. Blindly retrying the whole batch would duplicate the north rows. The agent can see exactly which file needs another pass and which one is already done.
The failures you actually have to design for
Most agent failures fall into three flavors, and they want different responses.
Transient failures are the easy ones. Timeouts, rate limits, an overloaded upstream. You don’t need a language model to improvise around a 429. You need backoff and a way to know whether the retry is safe.
State drift is harder. The agent made a plan against one version of the world, and the world moved. A human updated the record. Another job ran. Permissions changed. Recovery here usually means re-checking reality, not resuming the original plan.
Partial side effects are the dangerous category. Step three wrote something, step four failed before it confirmed. The downstream system accepted half a batch. The job started but the terminal status never came back. If the agent can’t tell “not started” from “already committed,” every retry is a coin flip. This is why idempotency keys, dedupe windows, and write semantics aren’t optional once you connect agents to anything that matters.
Agents start to look like workflow engines
The closer you push an agent toward real operational work, the more it begins to need the same things workflow engines have offered for years. Checkpoints. Retries. Task state. Compensation paths. Human approval boundaries. Observability.
This isn’t because workflow engines are glamorous. They aren’t. It’s because the problems are real, and you don’t get to skip them just because the orchestrator is now an LLM.
The model is still doing important work — interpreting intent, picking actions, adapting to ambiguity, explaining what it did. But you do not want the model to be the only place that remembers what happened. The transcript is not your system of record. Pretending it is will get you into trouble fastest in exactly the scenarios where recovery matters most.
What this looks like in practice
When teams move from fragile demo to something they can put in front of a customer, they usually converge on the same shape. Plan a bounded task. Execute one meaningful step. Write the outcome to durable state. Check what side effects actually occurred. Then retry, resume, or escalate based on policy.
For a data ingestion job — which I deal with constantly at Datris — don’t treat the tool call itself as success. The tool call accepted a request. That’s all it did. Capture the job ID, observe status, record the terminal outcome, and only then move on. Collapsing “request accepted” and “work completed” into the same mental model is how you get an agent cheerfully reporting “Done” while the pipeline is still grinding, or already on fire.
Trust is the other half
Recovery isn’t only infrastructure. It’s a trust contract with the user.
People will tolerate delays. They’ll tolerate a clean error. They’ll even tolerate being asked for approval. What they won’t tolerate is uncertainty — an agent that says “Done” when it isn’t, or silently retries an action with side effects, or quietly loses track of a step that already committed.
Once a user starts double-checking the agent’s work by hand, you no longer have automation. You have supervision overhead with extra steps.
A production agent should be able to say things like “the export job is still running, I’ll wait,” or “upstream is rate-limiting, retry is safe, backing off for 30 seconds,” or “a partial write may have occurred, checking the destination before I retry.” That isn’t less intelligent behavior. It’s the kind of behavior you can actually deploy.
Where this goes
We’ve established that models can reason, call tools, and produce decent drafts. The next thing they have to prove is that they can operate in the messy middle of real systems without making the messy middle worse.
That means task state you can inspect, idempotency you can rely on, side effects you can bound, async work treated as a first-class citizen instead of an inconvenience. Systems that can resume instead of restart, and verify instead of assume.
If you’re building agents for production, the recovery loop is where the architecture proves itself. That’s where I’d spend the time.
We’re building this layer at datris.ai — pipeline state agents can inspect, MCP tools that return job IDs instead of acks, and an execution model that knows the difference between “request accepted” and “work completed.” Repo’s at github.com/datris/datris-platform-oss.