For a year I’ve argued that agents should take over the data work we used to do by hand. Building the pipeline. Deciding where data lands. Recovering when a feed breaks at 2 a.m. So you’d expect the next move to be an agent that owns orchestration too: when everything runs, in what order, what to do when a step fails. Retire the scheduler. Retire the DAG.
I’d argue the opposite. The DAG and its retries are some of the most valuable machinery we’ve built in twenty years of data engineering. An agent should sit next to them and do the one thing they were never designed to do.
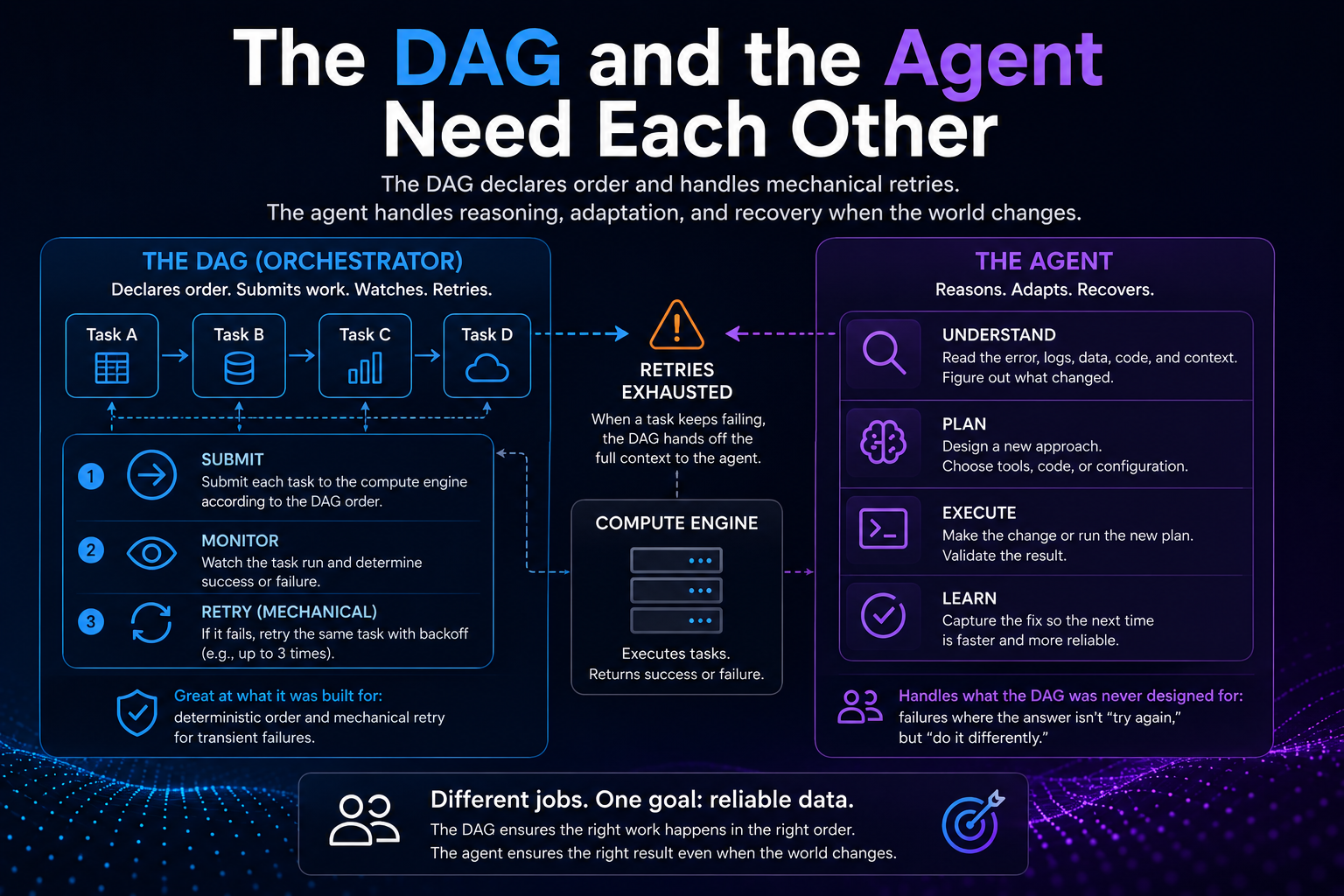
A DAG is a promise about order
Strip away the tooling and a DAG is a declaration of dependencies. Load B only after A succeeds. It’s a graph of “this, then that,” run the same way every time, readable before a single task fires. A DAG is good because it doesn’t think. Ask it to think and you’ve broken the one guarantee you built it for.
Retries bet that nothing changed
The most underrated line in any DAG is the retry policy. A task fails, the orchestrator backs off and runs it again. Three times, five, with a growing delay. It works astonishingly often, because most production failures are transient: a network blip, a lock that clears, a service mid-redeploy. Run the identical task thirty seconds later and it sails through.
But look at the assumption. A mechanical retry bets that running the exact same task again is worth doing, that the failure was a hiccup and the world is unchanged. When that’s right, retry is free reliability and needs no intelligence at all. The reason it needs none is also the reason it has a ceiling.
The other kind of failure
The bet is wrong more often than we admit. The source added a column and the parse chokes. The API quietly moved the records under a different key. Point a retry policy at either and you get five identical failures, just slower. The task itself is no longer correct. The world changed and the instruction didn’t.
A retry policy has no model of why something failed, only that it did. It can re-run. It cannot re-think. And re-thinking is the whole job: read what came back, work out what changed, run the adjusted version. That’s not a retry. That’s recovery, and recovery takes judgment a backoff timer doesn’t have.
For years we’ve papered over this by hand. The retries exhaust themselves, someone gets paged, and a person does the re-thinking the retry couldn’t. The DAG didn’t recover. A tired engineer did, at 3 a.m., doing work the orchestrator had no way to express.
The boundary
Two kinds of retry, one word for both. The mechanical kind, same task again later, belongs to the DAG: cheap, deterministic, no tokens. The reasoning kind, a different approach because the last one is no longer valid, belongs to the agent.
The line is whether doing the same thing again could plausibly work. A transient failure on an idempotent task could, so let the orchestrator handle it. A task guaranteed to fail the same way every time could not, and no retry will save you there. When a failure survives the retries, that exhaustion is the signal. Hand it to the agent, which doesn’t re-run the task. It reads the failure and rebuilds.
What the agent doesn’t replace
There’s a pull to claim the new thing replaces everything before it. The dashboard, the scheduler, the DAG, the on-call engineer. Cleaner story, and wrong.
Twenty years of orchestration got something right: deterministic order and mechanical retry are the correct tools for transient failures and fixed dependencies. We asked them to also cover the failures that aren’t transient, and there they quietly fail, because re-running a broken assumption faster doesn’t make it true. That’s the gap the agent fills.
So the DAG stays. The retries stay. The dependency graph your team spent years getting right stays. The agent takes the one class of failure that was never a scheduling problem to begin with. The kind where the answer isn’t again. It’s differently. They need each other. The mistake was ever asking one of them to be both.
Todd Fearn is the founder and CEO of Datris, an open-source, agent-native data platform. He has spent thirty years building production data infrastructure for financial institutions including Goldman Sachs, Bridgewater, Deutsche Bank, and Freddie Mac, and has founded several venture-backed companies.