A year ago, the most ambitious thing most people had seen an AI agent do with a data system was answer a question over a table somebody had already loaded for it.
That bar moved.
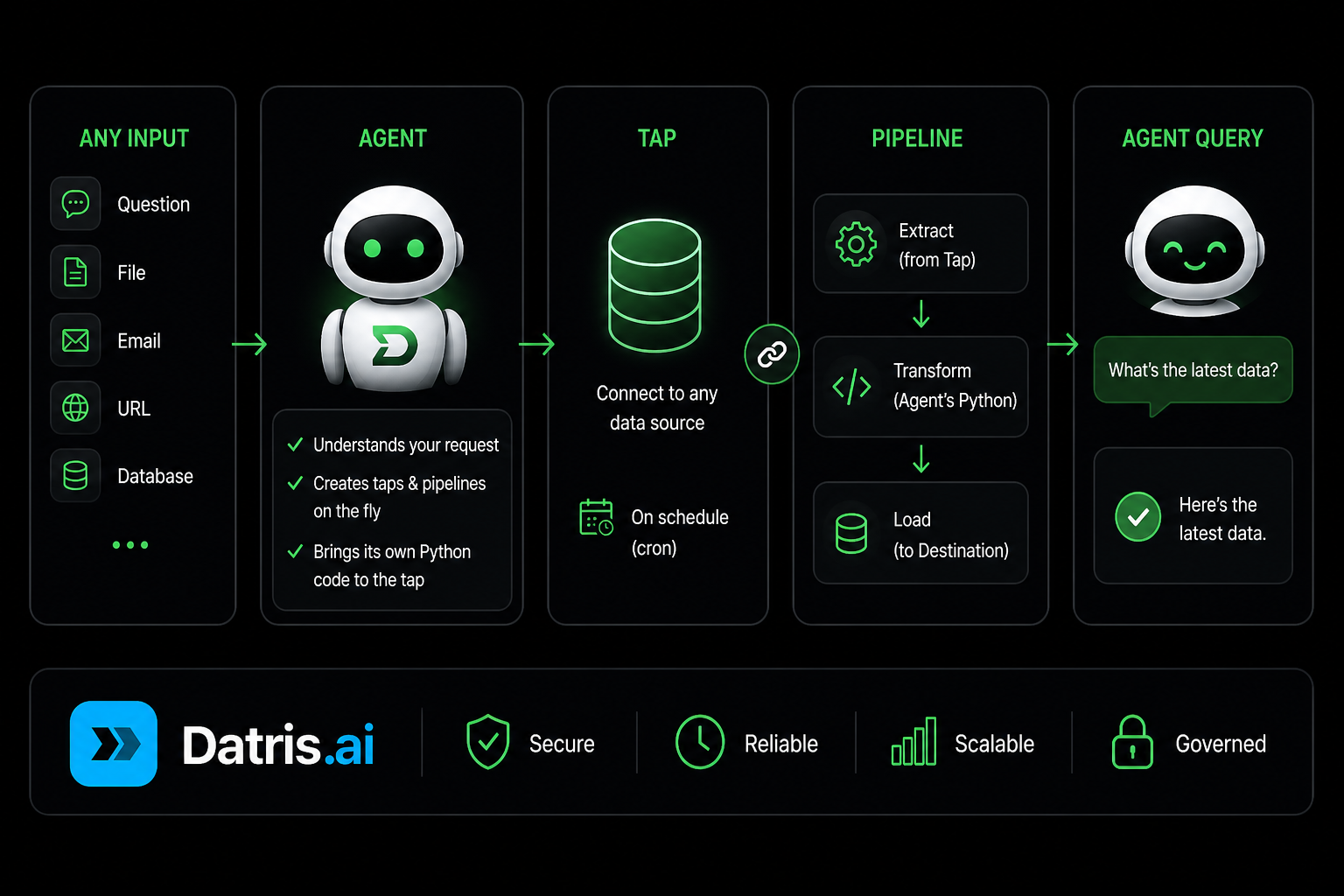
Today, an agent can sit in front of an empty Datris instance, decide it wants market data, mint its own API key secret for the upstream provider, generate the Python that fetches the data, run that script, watch the rows land in Postgres and a vector store, and then answer a question on top of what it just produced.
No human writes the script. No human stores the credential. No human babysits the pipeline. The agent does the whole loop.
That sounds like a marketing sentence. It’s also a literal description of what the platform does today, and it took a surprising amount of plumbing to make real.
This post is a tour of what that loop looks like in practice and what it took to close the last gaps.
The three gaps any agent hits against a data MCP server
Forget Datris for a minute.
Imagine you’re building an agent and you wire it up to whatever MCP server fronts your team’s data — could be a vendor’s, could be one your platform team shipped last quarter. The first time you actually try to let the agent do something end to end, the same three gaps tend to surface. They aren’t specific to any one product. They’re what happens when you put an LLM in front of a system that was originally designed for humans or for traditional API clients.
- The agent has no good way to bring data in by itself. Query and search tools tend to be polished. Ingestion is usually a placeholder — “upload a file,” “POST to this endpoint.” That’s fine if a human is dropping the file. It’s useless if the agent is trying to keep a dataset fresh against a moving upstream API.
- The agent has no place to put its own secrets. Most platforms have one big bag of credentials the operator configured at install time. Hand the keys to an agent and it’s all-or-nothing — full access or nothing. Multi-agent setups are worse, because every agent shares the same namespace and stomps on each other.
- The agent can’t tell whether anything actually landed. The tool call returns “success” the moment the request is accepted, but the work it triggered is async. The agent queries ten seconds later, finds an empty table, and either panics or hallucinates a result. This breaks essentially every agent that doesn’t know to wait for downstream confirmation.
These are the questions to ask of any data MCP server before you let an agent drive it. They’re not novel observations — they’re just what shakes out the moment you stop demoing and start letting the agent run unattended.
Datris closes all three. Taps give the agent a way to install its own ingestion (Gap 1). The _type=tap secret scoping enforced at the MCP layer gives it a private credential namespace it can’t escape (Gap 2). The publisherToken model lets it poll for actual completion instead of mistaking acceptance for success (Gap 3). Together, those three are what make the loop work — and not coincidentally, they’re what an agent-native data layer ends up needing regardless of who builds it.
The loop, with the actual tool names

Here’s what an agent does, in order, when it wants to bring a new dataset into Datris and use it. Every step below is an MCP tool call.
Step 1 — Stand up the destination pipeline.
create_pipeline(
pipeline="rates",
destination="postgres",
content="<base64 sample CSV>"
)A pipeline in Datris is the destination contract: where the data lands, what shape it takes, what validation runs on the way in. The agent doesn’t author a schema by hand. It hands create_pipeline a small sample of representative data and a destination type, and the platform infers the schema. The agent gets the inferred schema back and can move on.
This is the first thing the agent has to do, because everything downstream — the tap, the secret it needs, the publisher token it’ll watch — refers to a pipeline that already exists.
Step 2 — Provision its own credential.
create_tap_secret(name="fred-api-key", value={"apiKey": "..."})The agent reads its upstream credentials from its own environment and pushes them into Vault as tap-scoped secrets. These get tagged _type=tap and the MCP layer enforces a hard rule: agents can only modify or delete secrets they own. The human-owned Platform secrets the operator set up at install time are off-limits. An agent gone rogue cannot rewrite your anthropic-key.
This is the piece that mattered most for multi-agent deployments. Each agent can manage its own credential namespace without colliding with the operator or with peer agents.
Step 3 — Build a tap.
create_tap(
name="fred_quotes",
script="""
import os
from fredapi import Fred
def fetch():
fred = Fred(api_key=os.environ['FRED_API_KEY'])
series = fred.get_series_latest_release('DGS10').reset_index()
return [{"date": str(r['index']), "yield": float(r['DGS10'])}
for _, r in series.iterrows()]
""",
target_pipeline="rates",
secret_name="fred-api-key",
cron_expression="0 0 * * * ?",
packages=["fredapi"]
)A tap in Datris is a small Python program that the platform runs on a schedule and pushes rows into a pipeline. The agent declares its own pip dependencies and sets a cron_expression for ongoing execution. The target_pipeline is the one it just created in Step 1.
The platform also accepts a plain-English instruction instead of a script — the platform’s own AI will generate the Python for you. That path exists mostly for humans clicking through the UI. Agents should almost always bring their own code.
The reason is straightforward: the agent is already an LLM. Asking the platform to round-trip through another LLM to write Python adds a minute or two of latency, an extra hop of indirection, and a generation step the calling agent then has to read and validate anyway. Skipping it is faster, more reliable, and more debuggable. The agent already knows what the records should look like — it just wrote the pipeline schema in Step 1. Writing the fetcher itself keeps that context intact.
Bring-your-own-code is the agent path. Instruction-driven generation is the human-in-the-UI path. Use the right one.
This step matters more than it looks for a different reason too. The agent is not signing up to keep running the tap. It’s installing a recurring job into the platform. Once the cron is set, the platform owns execution forever after.
Step 4 — Run it and actually know whether the data landed.
run_tap("fred_quotes")The response includes three fields that close the async-confirmation gap:
persisted: true— the script reached MinIO and the publisher accepted itpersistedReason— a human-readable explanation ifpersistedis falsepublisherToken— a single token covering every ingestion job this tap run submitted
The publisherToken matters because a single tap run can fan out into many ingestion jobs — one per document in a JSON dump, for instance. Without a single token covering the whole batch, the agent would have to track N tokens and poll each independently. Instead it polls once:
get_pipeline_status(publisher_token=<token>)…until every row reaches end or error state. Then it queries. No more racing the pipeline.
Step 5 — Discover what it just made.
list_postgres_tables()
list_postgres_columns(table="rates")The agent doesn’t have to be told the schema. It can read it back from the platform after the data lands. This matters more than it sounds — it means a single agent can operate against pipelines another agent created, because the schema is discoverable, not hardcoded.
Step 6 — Answer a question.
query_natural(table="rates", question="What's the 10-year yield trend over the last six months?")Or, for something that needs RAG:
search_pgvector(query="treasury yield curve inversion", collection="rates_embed")
ai_answer(query="...", context=<search results>)The agent goes from “I have nothing” to “I have an answer the user trusts” in six MCP calls. It owns every piece of the path it walked.
The agent walks away. The platform keeps running.
This is the part of the story that I think gets undersold.
The naive version of “agentic data” puts the agent in the loop forever. Every refresh of the dataset is another tool call. Every poll, every fetch, every retry — the agent has to be there. Burn enough tokens and that model breaks down fast.
The cron-scheduled tap inverts that. Once the agent calls create_tap with a cron_expression, it’s done. The platform’s scheduler owns execution from that point on. Every hour, every six hours, every weekday at 4am — whatever the agent specified — the tap runs without anyone present. New rows land. The pipeline ingests them. The destination updates.
The agent doesn’t poll. The agent doesn’t wake up. The agent doesn’t pay tokens to babysit a job that’s working fine.
It only re-engages when something interesting happens — a tap failure surfaces in the log, a user asks a new question, an upstream API changes shape. The rest of the time, the platform runs on its own.
That changes what the agent actually is in this architecture. It’s not a worker. It’s an architect. It builds the data infrastructure once, then steps back. The infrastructure runs on cron, on schedule, indefinitely — exactly the way human-built data infrastructure has always run, except the human in this case was an LLM with an MCP client.
That’s a much more honest model for production agents. The expensive thing (the LLM) does setup work. The cheap thing (the platform’s scheduler, written in Scala, running on a JVM, executing Python in a sandbox) does the recurring work. The agent shows back up when there’s something worth thinking about.
What’s distinctively agent-native here
A lot of platforms expose MCP tools. The interesting question is whether the platform was designed for an agent to drive it, or whether MCP got bolted onto a UI-first product after the fact.
A few things in Datris only make sense if you assume the consumer is an AI:
Server instructions delivered at handshake. When an agent connects, the MCP server returns a block of workflow guidance in its initialize response — exact polling pattern for get_pipeline_status, when not to call slow tools, how to interpret persisted and persistedReason. The agent injects that into its system prompt automatically. Operational rules live with the platform, not with every agent author who has to read the docs.
Self-diagnosing errors. When a tap script fails because the platform can’t find it, the response says exactly that, with a flag (scriptMissing) the agent can branch on. Same for MinIO failures. The platform writes its errors in language an agent can act on, not in language a human reads off a dashboard.
Schema inference instead of schema authoring. The agent never writes a pipeline config. It hands create_pipeline some sample data and a destination type. The platform infers the schema. The agent just confirms.
Discovery as a first-class tool. discover_source lets an agent ask “what datasets does yfinance expose?” and get back a structured catalog with parameters and tap-instruction templates. That’s discovery at the data-source level, on top of MCP’s discovery at the tool level. Two layers, both designed to keep the agent from having to know things in advance.
Agent-owned secrets with platform-enforced scoping. The _type=tap rule isn’t a convention. It’s enforced at the MCP layer, not the API layer. An agent that tries to delete a Platform secret gets refused before the request reaches the secret store.
These are the things that turn “the agent can call our tools” into “the agent can run a slice of our platform without breaking it.”
The pattern: an agent owns its slice of the data plane
The mental model that keeps coming back as I build this out is that an agent should own a slice of the data plane — its own taps, its own secrets, its own pipelines — but never the whole thing.
The platform draws the line. Operators own the install-time configuration, the AI provider keys, the database itself. Agents own the data sources they introduced, the credentials those sources need, and the pipelines they’re responsible for. Other agents can read and query everything. They can only mutate their own slice.
This is the closest thing I’ve found to a workable production model for letting agents do real work in a data system without giving them root.
It also generalizes. The same pattern works whether you’re letting a single research agent build itself a workspace, letting a team of domain agents each own their own data sources in a multi-tenant deployment, or letting an enterprise customer hand off chunks of their data ops to autonomous workers without losing the ability to audit or revoke.
Why this matters now
For most of 2025, the AI agent conversation was about reasoning quality and tool calling. Both of those got good enough that they’re no longer the bottleneck.
The bottleneck moved to the systems agents talk to.
A model that can plan ten steps ahead is wasted on a platform that can’t tell it whether step three landed. A multi-agent architecture is meaningless if every agent shares one credential namespace and overwrites the others’ work. A control plane is hard to build on top of a tool layer that doesn’t expose state.
The work of the next year, in my opinion, is making data platforms behave like first-class participants in agent workflows — durable, observable, scoped, self-describing. The MCP protocol is the cleanest contract we’ve had for that, but the platform on the other side of the protocol has to actually be designed for it.
Datris is one attempt at that. It’s open source. The whole loop I described above runs in the example agent in the repo. The MCP tool definitions live in mcp-server/server.py and the docs are at docs.datris.ai.
Six MCP calls from nothing to an answer. That’s the bar now. Build accordingly.
Todd Fearn is the founder of Datris.ai and has spent 25+ years building data infrastructure and AI solutions across financial services, healthcare, and enterprise — from Goldman Sachs and Bridgewater Associates to Deutsche Bank, Freddie Mac, and beyond.