Most data platforms assume the hard part starts after the data shows up.
In my experience it’s the opposite. Getting the data in reliably is where most of the pain lives.
You know the drill. An API has pagination quirks. A vendor renames a field on a Friday afternoon. A spreadsheet lands in a shared bucket every morning from someone who left the company two quarters ago. Marketing wants Salesforce data. Compliance wants regulatory filings. Risk wants market data going back to 2007. Everybody wants their stuff pulled into a common place before anyone can actually do anything with it.
For 25+ years I watched this play out the same way at every shop I worked at. Somebody writes a Python script. Somebody else bolts on credentials. A scheduler shows up. Logs end up in a directory nobody monitors. Six months later the script is still running, kind of, and nobody remembers who owns it.
That model doesn’t survive contact with agents.
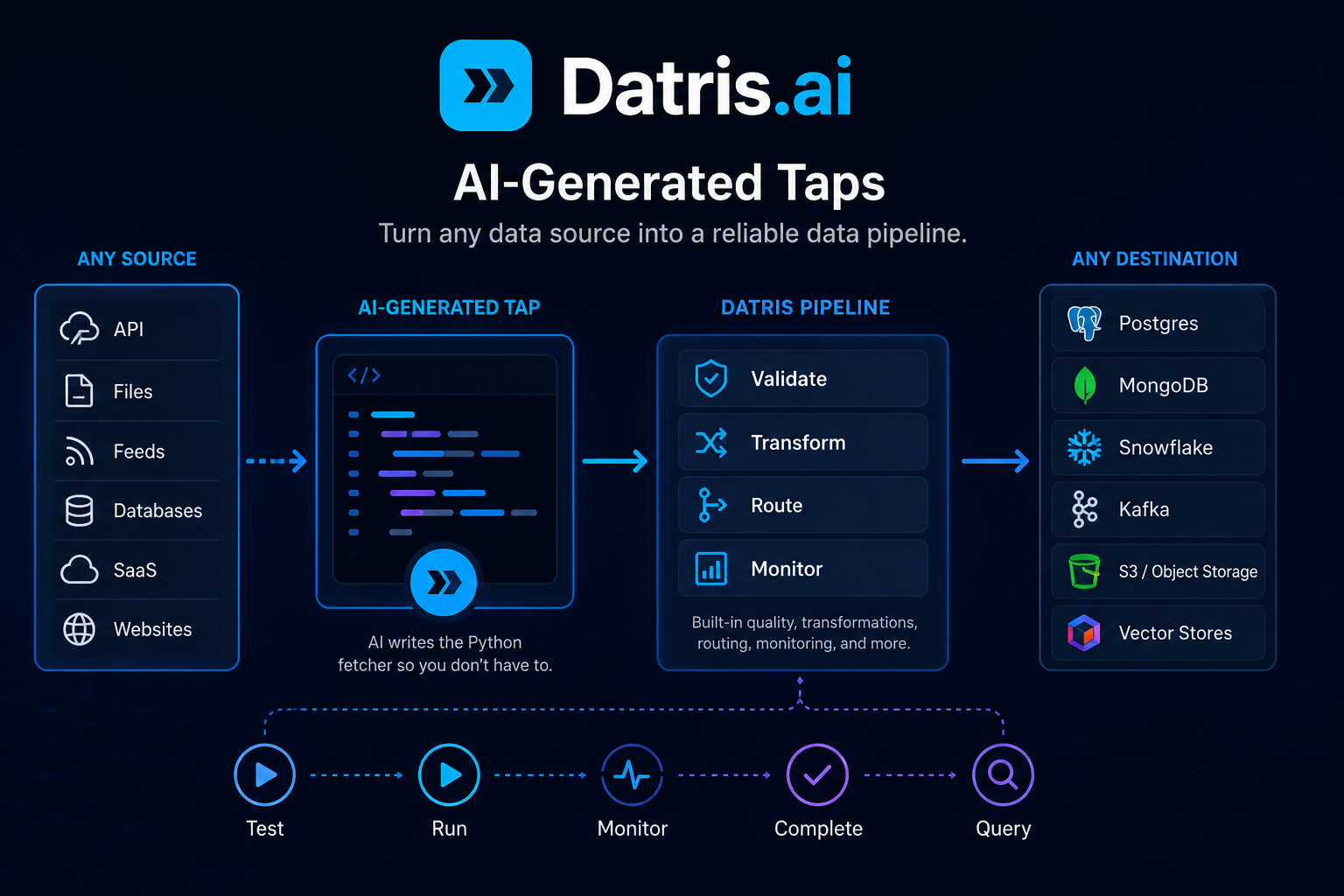
If an AI agent is going to help you run the data stack, it can’t tap out at “please paste a CSV here.” It needs to discover sources, write the ingestion logic, run it, watch it, and hand the results to whatever comes next. That’s what Datris taps are for.
What a tap actually is
A tap is a small Python fetcher. It connects to a source and returns data in a shape Datris can work with. Sources can be REST APIs, RSS feeds, databases, S3 buckets, websites, folders of PDFs, SaaS exports. If you can read it programmatically, you can wrap it in a tap.
Two flavors. Structured taps return rows or JSON objects. Document taps return files that get staged, chunked, embedded, and pushed into a vector database for RAG.
The interesting part isn’t that we run Python. Lots of things run Python. The interesting part is that a tap is a first-class object on the platform. You can generate it, review it, schedule it, test it, log it, connect it to a pipeline, and operate it through MCP. An agent can do all of that without ever touching a server.
That turns ingestion from “open a Jira ticket and wait two weeks” into “describe the source, get an operational ingestion path.”
From prompt to pipeline
A real request looks like this:
Pull the latest SEC company facts for these tickers once a day, normalize the numeric fields, and load them into Postgres so I can run queries.
Or:
Watch this S3 folder for new PDFs. Skip the ones we’ve already done. Load the rest into Qdrant so support agents can answer questions out of the documents.
In Datris, an agent walks that through end to end:
- Pick or create the destination pipeline.
- Generate the tap from the source description.
- Wire up credentials from Vault-backed tap secrets if needed.
- Test-run without persisting anything.
- Run for real.
- Poll ingestion status until the pipeline finishes.
- Query the destination to confirm the load.
Step six is where most demos quietly fall over. The script returns data and everybody claps. But did the data actually land? Did validation pass? Did the downstream pipeline finish? Datris keeps “the tap fetched some rows” separate from “the pipeline processed them” and exposes both through the API and MCP. Tap runs return a publisher token, and the agent uses it to follow every job the run kicked off.
I’d rather know my pipeline failed than be told it succeeded because a Python script exited zero.
A concrete example
Say you want to ingest a public status feed every hour:
import os, requests
from datetime import datetime, timezone
def fetch():
_tl = os.environ.get("DATRIS_TAP_TEST_LIMIT")
sample_cap = int(_tl) if _tl else None
session = requests.Session()
session.headers.update({"User-Agent": "Mozilla/5.0 (compatible; datris-tap/1.0)"})
resp = session.get("https://example.com/status.json", timeout=30)
resp.raise_for_status()
rows = []
for item in resp.json().get("incidents", []):
if sample_cap is not None and len(rows) >= sample_cap:
break
rows.append({
"incident_id": item.get("id"),
"service": item.get("service"),
"state": item.get("state"),
"message": item.get("message"),
"observed_at": datetime.now(timezone.utc).isoformat(),
})
return rowsIn the old setup that script is maybe ten percent of the actual project. You still owe schema handling, validation, transformations, destination writes, scheduling, status reporting, secret management, and retries.
In Datris the tap is just the source adapter. The pipeline does the rest. Same rows can be routed to Postgres, MongoDB, Kafka, ActiveMQ, object storage, or a vector store depending on how the pipeline is wired up.
Document taps are where this gets really useful. The tap returns documents with a URI, filename, and content. Datris keeps a ledger of what’s been seen along with content hashes, so unchanged files get skipped on the next run. This kills the most common RAG failure I see in the wild: re-embedding the same folder every night because nobody bothered to track what changed. Embeddings aren’t free, and neither is your Snowflake bill.
Why agents need this
Agents are decent at orchestrating systems that give them stable handles. They are awful at guessing whether last night’s cron job worked, scraping logs for “ERROR,” or remembering which script wrote to which table. That isn’t intelligence. It’s archaeology.
A tap gives an agent something concrete to operate on. Create it. Test it. Run it. Read its logs. Schedule it. Connect it to a pipeline. Inspect the document ledger. Clear an entry and reprocess.
Those are verbs, not vibes.
The broader bet behind Datris is that agents shouldn’t have to SSH into a box and improvise. They should work through real platform APIs that expose the lifecycle of data work.
What you get out of it
For engineering, fewer one-off ingestion scripts hiding in repos, laptops, and crontabs.
For data teams, source acquisition stops being a separate cottage industry that nobody owns. It becomes part of the same lifecycle as validation, transformation, routing, and query.
On the AI side, keeping agent memory, vector stores, and analytical tables fresh stops being a custom job for every new source.
And for whoever has to operate this thing, the boundary is clean. The tap fetches. The pipeline governs. Source-specific code stays small. Quality rules, transformations, credentials, observability, delivery. The stuff that should be centralized actually is.
If you want to try it, head to datris.ai or grab the Datris Platform OSS repo. The Datris Assistant runs the whole loop: spin up a pipeline, generate a tap, run it, watch the data land. Describe the source you want; the Assistant handles the rest.
Todd Fearn is the founder of Datris.ai. He has been building AI solutions and data infrastructure for financial services for 25+ years, including stints at Goldman Sachs, Bridgewater Associates, Deutsche Bank, and Freddie Mac.